This project considers how explanations can be used to aid in ML robustness, either by directly identifying issues or by helping a human make better decisions. This relates to the causal ML project as causality can provide a natural explanation in certain cases. Overall, we view explanations as a way to enhance robustness of ML.
Explaining distribution shifts in histopathology images across hospitals.
Explainable AI
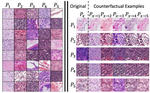
 Explaining distribution shifts in histopathology images across hospitals.
Explaining distribution shifts in histopathology images across hospitals.
Explainable AI
David I. Inouye
Assistant Professor
I research trustworthy ML methods that are robust to imperfect distributional and computational assumptions using explainability, causality, and collaborative learning.
Publications
(New!) Your VAR Model is Secretly an Efficient and Explainable Generative Classifier
Generative classifiers, which leverage conditional generative models for classification, have recently demonstrated desirable …
Att-Adapter: A Robust and Precise Domain-Specific Multi-Attributes T2I Diffusion Adapter via Conditional Variational Autoencoder
Text-to-Image (T2I) Diffusion Models have achieved remarkable performance in generating high quality images. However, enabling precise …

Enhanced Controllability of Diffusion Models via Feature Disentanglement and Realism-Enhanced Sampling Methods
As Diffusion Models have shown promising performance, a lot of efforts have been made to improve the controllability of Diffusion …

Towards Explaining Distribution Shifts
A distribution shift can have fundamental consequences such as signaling a change in the operating environment or significantly …

StarCraftImage: A Dataset For Prototyping Spatial Reasoning Methods For Multi-Agent Environments
Spatial reasoning tasks in multi-agent environments such as event prediction, agent type identification, or missing data imputation are …
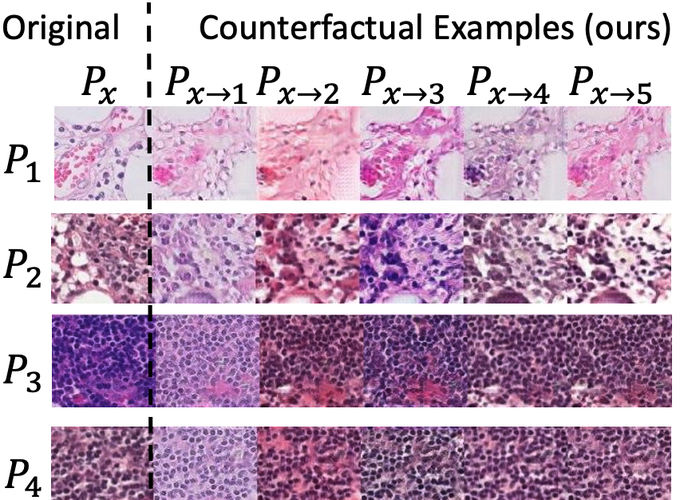
Towards Explaining Image-Based Distribution Shifts
Distribution shift can have fundamental consequences such as signaling a change in the operating environment or significantly reducing …
Shapley Explanation Networks
Shapley values have become one of the most popular feature attribution explanation methods. However, most prior work has focused on …

Feature Shift Detection: Localizing Which Features Have Shifted via Conditional Distribution Tests
While previous distribution shift detection approaches can identify if a shift has occurred, these approaches cannot localize which …
Automated Dependence Plots
In practical applications of machine learning, it is necessary to look beyond standard metrics such as test accuracy in order to …
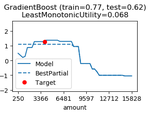
On the (In)fidelity and Sensitivity of Explanations
We consider objective evaluation measures of explanations of complex black-box machine learning models. We propose simple robust …
