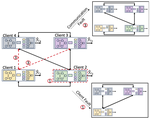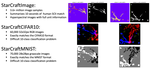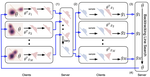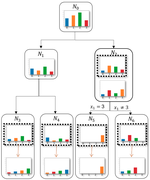
This project is focused on making collaborative learning, particularly on an unreliable and dynamic set of edge devices, robust to imperfect computational conditions. These could include faults in the devices or communication but could also include heterogeneity in the edge device datasets. We have explored robust collaborative learning and localized learning research diretions. We are currently exploring methods for handling device elasticity (i.e., adaptability to increasing the number of edge devices) and robustness to topology of peer-to-peer edge learning systems.
I co-organized the ICML 2023 Workshop on Localized Learning. Accepted papers on OpenReview.